Σύνταξη
df [ ( cond_1 ) & ( cond_2 ) ]Παράδειγμα 01
Κάνουμε αυτούς τους κωδικούς στην εφαρμογή 'Spyder' και θα χρησιμοποιήσουμε τον τελεστή 'AND' στις συνθήκες μας στα 'pandas' εδώ. Καθώς κάνουμε τους κωδικούς pandas, έτσι πρέπει πρώτα να εισαγάγουμε τα 'pandas ως pd' και θα λάβουμε τη μέθοδο του βάζοντας απλώς 'pd' στον κώδικά μας. Στη συνέχεια, δημιουργούμε ένα λεξικό με το όνομα 'Cond' και τα δεδομένα που εισάγουμε εδώ είναι 'A1', 'A2' και 'A3' είναι τα ονόματα των στηλών και προσθέτουμε '1, 2 και 3' στο ' A1', στο 'A2' υπάρχει '2, 6, και 4' και το τελευταίο 'A3', περιέχει '3, 4, και 5'.
Στη συνέχεια, προχωράμε στη δημιουργία του DataFrame αυτού του λεξικού χρησιμοποιώντας το 'pd.DataFrame' εδώ. Αυτό θα επιστρέψει το DataFrame των παραπάνω δεδομένων λεξικού. Το αποδίδουμε επίσης παρέχοντας το 'print ()' εδώ, και μετά από αυτό, εφαρμόζουμε ορισμένες προϋποθέσεις και επίσης χρησιμοποιούμε τον τελεστή '&' σε αυτήν την συνθήκη. Η πρώτη συνθήκη εδώ είναι ότι 'A1 >= 1', και μετά βάζουμε τον τελεστή '&' και τοποθετούμε μια άλλη συνθήκη που είναι 'A2 < 5'. Όταν το εκτελέσουμε αυτό, θα επιστρέψει το αποτέλεσμα εάν 'A1 >=1' και επίσης 'A2 < 5'. Εάν εδώ πληρούνται και οι δύο προϋποθέσεις, τότε θα εμφανιστεί το αποτέλεσμα και εάν κάποια από αυτές δεν ικανοποιείται εδώ, τότε δεν θα εμφανίσει δεδομένα.
Ελέγχει και τις δύο στήλες 'A1' και 'A2' του DataFrame και στη συνέχεια επιστρέφει το αποτέλεσμα. Το αποτέλεσμα εμφανίζεται στην οθόνη επειδή χρησιμοποιούμε τη δήλωση 'print ()'.
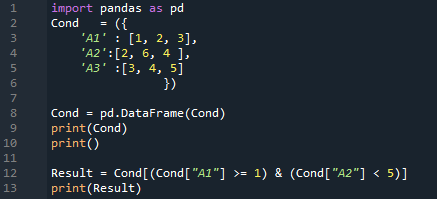
Το αποτέλεσμα είναι εδώ. Εμφανίζει όλα τα δεδομένα που έχουμε εισαγάγει στο DataFrame και στη συνέχεια ελέγχει και τις δύο συνθήκες. Επιστρέφει εκείνες τις σειρές στις οποίες 'A1 >=1' και επίσης 'A2 < 5'. Λαμβάνουμε δύο σειρές σε αυτήν την έξοδο επειδή ικανοποιούνται και οι δύο συνθήκες σε δύο σειρές.
Παράδειγμα 02
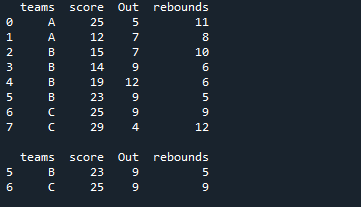
Σε αυτό το παράδειγμα, δημιουργούμε απευθείας το DataFrame μετά την εισαγωγή των 'pandas ως pd'. Το 'Team' DataFrame δημιουργείται εδώ, με τα δεδομένα να περιέχουν τέσσερις στήλες. Η πρώτη στήλη είναι η στήλη 'ομάδες' εδώ στην οποία βάζουμε 'A, A, B, B, B, B, C, C'. Στη συνέχεια, η στήλη δίπλα στις «ομάδες» είναι «βαθμολογία», στην οποία εισάγουμε «25, 12, 15, 14, 19, 23, 25 και 29». Μετά από αυτό, η στήλη που έχουμε είναι 'Out' και προσθέτουμε επίσης δεδομένα σε αυτήν ως '5, 7, 7, 9, 12, 9, 9 και 4'. Η τελευταία μας στήλη εδώ είναι η στήλη 'ριμπάουντ' που περιέχει επίσης ορισμένα αριθμητικά δεδομένα, τα οποία είναι '11, 8, 10, 6, 6, 5, 9 και 12'.
Το DataFrame ολοκληρώνεται εδώ, και τώρα πρέπει να εκτυπώσουμε αυτό το DataFrame, οπότε για αυτό, τοποθετούμε το 'print ()' εδώ. Θέλουμε να λάβουμε ορισμένα συγκεκριμένα δεδομένα από αυτό το DataFrame, γι' αυτό ορίζουμε ορισμένους όρους εδώ. Έχουμε δύο προϋποθέσεις εδώ και προσθέτουμε τον τελεστή 'AND' μεταξύ αυτών των συνθηκών, οπότε θα επιστρέψει μόνο εκείνες τις προϋποθέσεις που ικανοποιούν και τις δύο προϋποθέσεις. Η πρώτη συνθήκη που προσθέσαμε εδώ είναι η «βαθμολογία > 20» και μετά τοποθετούμε τον τελεστή «&» και την άλλη συνθήκη που είναι «Έξοδος == 9».
Έτσι, θα φιλτράρει εκείνα τα δεδομένα όπου η βαθμολογία της ομάδας είναι μικρότερη από 20 και επίσης τα άουτ της είναι 9. Φιλτράρει αυτά και αγνοεί τα υπόλοιπα, τα οποία δεν θα ικανοποιούν και τις δύο προϋποθέσεις ή καμία από αυτές. Εμφανίζουμε επίσης εκείνα τα δεδομένα που ικανοποιούν και τις δύο προϋποθέσεις, επομένως χρησιμοποιήσαμε τη μέθοδο 'εκτύπωση ()'.
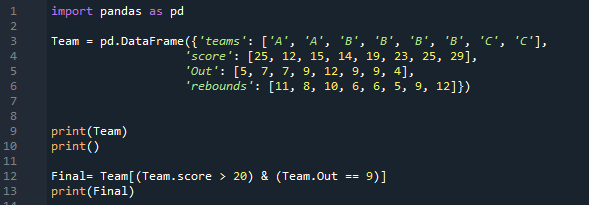
Μόνο δύο σειρές ικανοποιούν και τις δύο προϋποθέσεις, τις οποίες έχουμε εφαρμόσει σε αυτό το DataFrame. Φιλτράρει μόνο εκείνες τις σειρές στις οποίες η βαθμολογία είναι μεγαλύτερη από 20, και επίσης, τα άουτ τους είναι 9 και τα εμφανίζει εδώ.
Παράδειγμα 03
Στους παραπάνω κωδικούς μας, απλώς εισάγουμε τα αριθμητικά δεδομένα στο DataFrame μας. Τώρα, βάζουμε ορισμένα δεδομένα συμβολοσειράς σε αυτόν τον κώδικα. Μετά την εισαγωγή των 'pandas ως pd', προχωράμε στη δημιουργία ενός 'Member' DataFrame. Περιλαμβάνει τέσσερις μοναδικές στήλες. Το όνομα της πρώτης στήλης εδώ είναι 'Όνομα' και εισάγουμε τα ονόματα των μελών, τα οποία είναι 'Σύμμαχοι, Bills, Charles, David, Ethen, George και Henry'. Η επόμενη στήλη ονομάζεται 'Τοποθεσία' εδώ και έχει 'Αμερική. Καναδάς, Ευρώπη, Καναδάς, Γερμανία, Ντουμπάι και Καναδάς» σε αυτό. Η στήλη 'Κωδικός' περιέχει 'W, W, W, E, E, E και E'. Προσθέτουμε επίσης τους «πόντους» των μελών εδώ ως «11, 6, 10, 8, 6, 5 και 12». Αποδίδουμε το DataFrame 'Member' με τη χρήση της μεθόδου 'print ()'. Έχουμε καθορίσει ορισμένες συνθήκες σε αυτό το DataFrame.
Εδώ, έχουμε δύο προϋποθέσεις και προσθέτοντας τον τελεστή 'AND' μεταξύ τους, θα επιστρέψει μόνο συνθήκες που ικανοποιούν και τις δύο προϋποθέσεις. Εδώ, η πρώτη συνθήκη που έχουμε εισαγάγει είναι 'Τοποθεσία == Καναδάς', ακολουθούμενη από τον τελεστή '&' και η δεύτερη συνθήκη, 'σημεία <= 9'. Λαμβάνει αυτά τα δεδομένα από το DataFrame στο οποίο πληρούνται και οι δύο συνθήκες και, στη συνέχεια, έχουμε τοποθετήσει το 'print ()' το οποίο εμφανίζει εκείνα τα δεδομένα στα οποία και οι δύο συνθήκες ισχύουν.
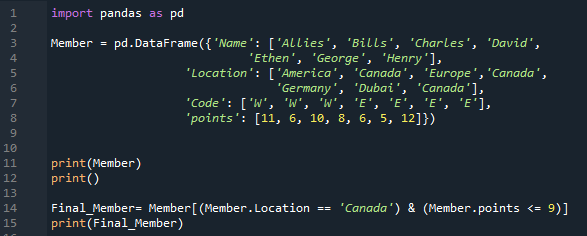
Παρακάτω μπορείτε να παρατηρήσετε ότι δύο σειρές εξάγονται από το DataFrame και εμφανίζονται. Και στις δύο σειρές, η τοποθεσία είναι 'Καναδάς' και οι πόντοι είναι λιγότεροι από 9.
Παράδειγμα 04
Εισάγουμε και τα 'pandas' και 'numpy' εδώ ως 'pd' και 'np', αντίστοιχα. Παίρνουμε τις μεθόδους 'pandas' τοποθετώντας 'pd' και τις μεθόδους 'numpy' τοποθετώντας το 'np' όπου χρειάζεται. Στη συνέχεια, το λεξικό που δημιουργήσαμε εδώ περιέχει τρεις στήλες. Στη στήλη «Όνομα» στην οποία εισάγουμε «Σύμμαχοι, Τζορτζ, Νίμι, Σαμουήλ και Γουίλιαμ». Στη συνέχεια, έχουμε τη στήλη 'Obt_Marks', η οποία περιέχει τους βαθμούς που έλαβαν οι μαθητές, και αυτοί οι βαθμοί είναι '4, 47, 55, 74 και 31'.
Δημιουργούμε επίσης μια στήλη για τα “Prac_Marks” εδώ που έχουν τους πρακτικούς βαθμούς του μαθητή. Τα σημάδια που προσθέτουμε εδώ είναι '5, 67, 54, 56 και 12'. Φτιάχνουμε το DataFrame αυτού του Λεξικού και μετά το εκτυπώνουμε. Εφαρμόζουμε το 'np.Logical_and' εδώ, το οποίο θα επιστρέψει το αποτέλεσμα σε μορφή 'True' ή 'False'. Επίσης αποθηκεύουμε το αποτέλεσμα αφού ελέγξουμε και τις δύο συνθήκες σε μια νέα στήλη, την οποία έχουμε δημιουργήσει εδώ με το όνομα “Pass_Status”.
Ελέγχει ότι το 'Obt_Marks' είναι μεγαλύτερο από '40' και το 'Prac_Marks' είναι μεγαλύτερο από το '40'. Εάν και τα δύο είναι αληθή, τότε θα αποδοθεί true στη νέα στήλη. διαφορετικά, αποδίδεται ψευδής.
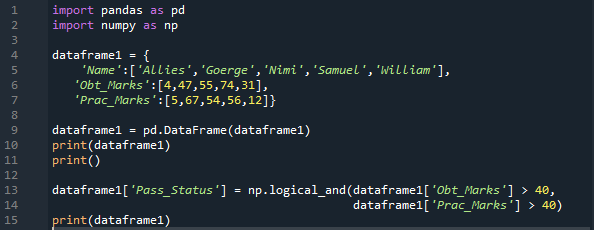
Η νέα στήλη προστίθεται με το όνομα 'Pass_Status' και αυτή η στήλη αποτελείται μόνο από 'True' και 'False'. Καθίσταται αληθές όταν οι βαθμοί που λαμβάνονται και επίσης οι πρακτικοί βαθμοί είναι μεγαλύτεροι από 40 και ψευδείς για τις υπόλοιπες σειρές.
συμπέρασμα
Ο κύριος στόχος αυτού του σεμιναρίου είναι να εξηγήσει την έννοια του 'και της κατάστασης' στα 'pandas'. Μιλήσαμε για το πώς να αποκτήσουμε αυτές τις σειρές όπου ικανοποιούνται και οι δύο προϋποθέσεις ή επίσης παίρνουμε αληθές για εκείνες όπου πληρούνται όλες οι προϋποθέσεις και ψευδείς για τις υπόλοιπες. Εξερευνήσαμε τέσσερα παραδείγματα εδώ. Και τα τέσσερα παραδείγματα που δημιουργήσαμε σε αυτό το σεμινάριο έχουν περάσει από αυτήν τη διαδικασία. Τα παραδείγματα σε αυτό το σεμινάριο έχουν όλα παρουσιαστεί προσεκτικά προς όφελός σας. Αυτό το σεμινάριο θα πρέπει να σας βοηθήσει να κατανοήσετε αυτή την ιδέα πιο ξεκάθαρα.