Γρήγορο περίγραμμα
Αυτή η ανάρτηση περιέχει τις ακόλουθες ενότητες:
- Πώς να χρησιμοποιήσετε έναν Async API Agent στο LangChain
- Μέθοδος 1: Χρήση σειριακής εκτέλεσης
- Μέθοδος 2: Χρήση ταυτόχρονης εκτέλεσης
- συμπέρασμα
Πώς να χρησιμοποιήσετε έναν Async API Agent στο LangChain;
Τα μοντέλα συνομιλίας εκτελούν πολλαπλές εργασίες ταυτόχρονα, όπως η κατανόηση της δομής του μηνύματος, η πολυπλοκότητά του, η εξαγωγή πληροφοριών και πολλά άλλα. Η χρήση του πράκτορα Async API στο LangChain επιτρέπει στο χρήστη να δημιουργήσει αποτελεσματικά μοντέλα συνομιλίας που μπορούν να απαντήσουν σε πολλές ερωτήσεις ταυτόχρονα. Για να μάθετε τη διαδικασία χρήσης του παράγοντα Async API στο LangChain, απλώς ακολουθήστε αυτόν τον οδηγό:
Βήμα 1: Εγκατάσταση Frameworks
Πρώτα απ 'όλα, εγκαταστήστε το πλαίσιο LangChain για να λάβετε τις εξαρτήσεις του από τον διαχειριστή πακέτων Python:
pip install langchain
Μετά από αυτό, εγκαταστήστε τη λειτουργική μονάδα OpenAI για να δημιουργήσετε το μοντέλο γλώσσας όπως το llm και να ορίσετε το περιβάλλον του:
pip εγκατάσταση openai
Βήμα 2: OpenAI Environment
Το επόμενο βήμα μετά την εγκατάσταση των μονάδων είναι στήσιμο του περιβάλλοντος χρησιμοποιώντας το κλειδί API του OpenAI και Serper API για να αναζητήσετε δεδομένα από το Google:
εισαγωγή εσείς
εισαγωγή getpass
εσείς . κατά προσέγγιση [ 'OPENAI_API_KEY' ] = getpass . getpass ( 'Κλειδί OpenAI API:' )
εσείς . κατά προσέγγιση [ 'SERPER_API_KEY' ] = getpass . getpass ( 'Κλειδί API Serper:' )
Βήμα 3: Εισαγωγή Βιβλιοθηκών
Τώρα που έχει ρυθμιστεί το περιβάλλον, απλώς εισαγάγετε τις απαιτούμενες βιβλιοθήκες όπως το asyncio και άλλες βιβλιοθήκες χρησιμοποιώντας τις εξαρτήσεις LangChain:
από langchain. πράκτορες εισαγωγή αρχικοποίηση_πράκτορα , load_toolsεισαγωγή χρόνος
εισαγωγή asyncio
από langchain. πράκτορες εισαγωγή Τύπος πράκτορα
από langchain. llms εισαγωγή OpenAI
από langchain. ανακλήσεις . stdout εισαγωγή StdOutCallbackHandler
από langchain. ανακλήσεις . ιχνηλάτες εισαγωγή LangChainTracer
από aiohttp εισαγωγή ClientSession
Βήμα 4: Ερωτήσεις ρύθμισης
Ορίστε ένα σύνολο δεδομένων ερωτήσεων που περιέχει πολλαπλά ερωτήματα που σχετίζονται με διαφορετικούς τομείς ή θέματα που μπορούν να αναζητηθούν στο διαδίκτυο (Google):
ερωτήσεις = ['Ποιος είναι ο νικητής του πρωταθλήματος U.S. Open το 2021' ,
'Ποια είναι η ηλικία του φίλου της Olivia Wilde' ,
'Ποιος είναι ο νικητής του παγκόσμιου τίτλου της Formula 1' ,
'Ποιος κέρδισε τον τελικό γυναικών του US Open το 2021' ,
«Ποιος είναι ο σύζυγος της Beyonce και ποια είναι η ηλικία του» ,
]
Μέθοδος 1: Χρήση σειριακής εκτέλεσης
Μόλις ολοκληρωθούν όλα τα βήματα, απλώς εκτελέστε τις ερωτήσεις για να λάβετε όλες τις απαντήσεις χρησιμοποιώντας τη σειριακή εκτέλεση. Σημαίνει ότι μία ερώτηση θα εκτελείται/εμφανίζεται κάθε φορά και θα επιστρέφει επίσης τον πλήρη χρόνο που απαιτείται για την εκτέλεση αυτών των ερωτήσεων:
llm = OpenAI ( θερμοκρασία = 0 )εργαλεία = load_tools ( [ 'google-header' , 'llm-math' ] , llm = llm )
μέσο = αρχικοποίηση_πράκτορα (
εργαλεία , llm , μέσο = Τύπος πράκτορα. ZERO_SHOT_REACT_DESCRIPTION , πολύλογος = Αληθής
)
μικρό = χρόνος . perf_counter ( )
#configuring timecounter για να λάβετε τον χρόνο που χρησιμοποιείται για την πλήρη διαδικασία
Για q σε ερωτήσεις:
μέσο. τρέξιμο ( q )
παρήλθε = χρόνος . perf_counter ( ) - s
#print ο συνολικός χρόνος που χρησιμοποιήθηκε από τον πράκτορα για τη λήψη των απαντήσεων
Τυπώνω ( φά 'Η σειρά εκτελέστηκε σε {elapsed:0.2f} δευτερόλεπτα.' )
Παραγωγή
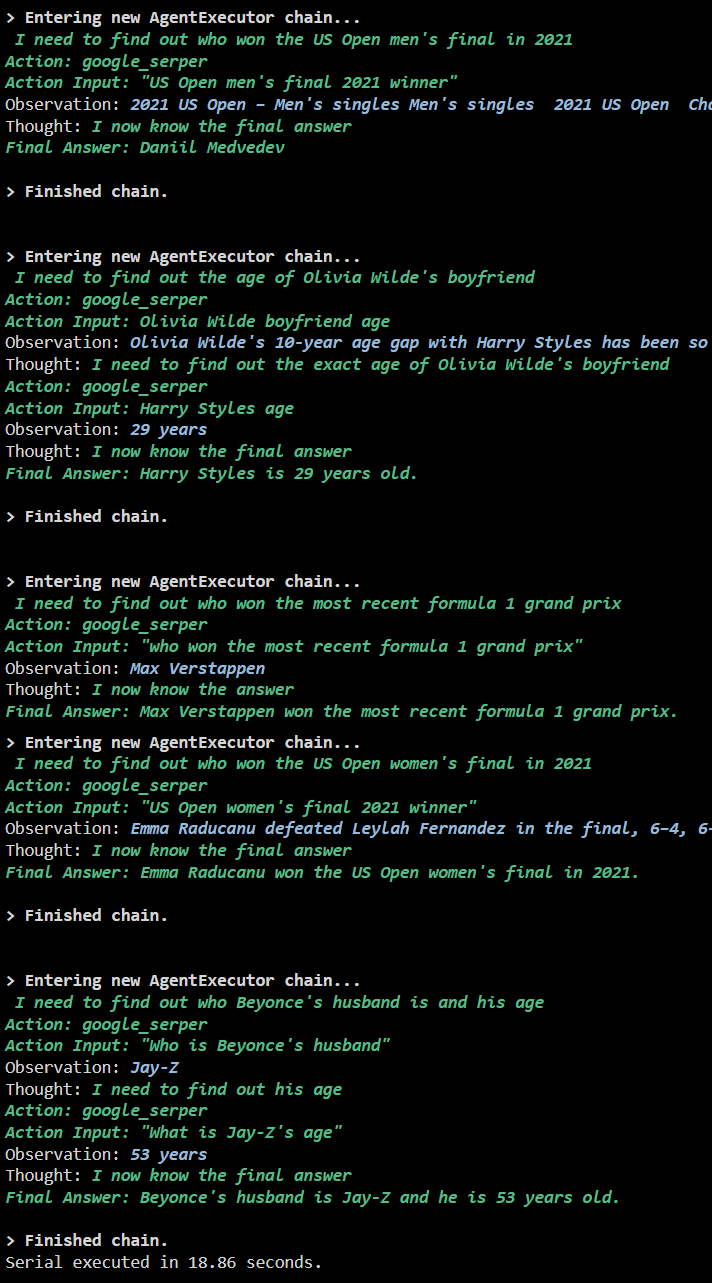
Το παρακάτω στιγμιότυπο οθόνης δείχνει ότι κάθε ερώτηση απαντάται σε ξεχωριστή αλυσίδα και μόλις ολοκληρωθεί η πρώτη αλυσίδα, τότε η δεύτερη αλυσίδα γίνεται ενεργή. Η σειριακή εκτέλεση απαιτεί περισσότερο χρόνο για να ληφθούν όλες οι απαντήσεις μεμονωμένα:
Μέθοδος 2: Χρήση ταυτόχρονης εκτέλεσης
Η μέθοδος ταυτόχρονης εκτέλεσης λαμβάνει όλες τις ερωτήσεις και λαμβάνει τις απαντήσεις τους ταυτόχρονα.
llm = OpenAI ( θερμοκρασία = 0 )εργαλεία = load_tools ( [ 'google-header' , 'llm-math' ] , llm = llm )
#Configuring agent χρησιμοποιώντας τα παραπάνω εργαλεία για να λαμβάνετε απαντήσεις ταυτόχρονα
μέσο = αρχικοποίηση_πράκτορα (
εργαλεία , llm , μέσο = Τύπος πράκτορα. ZERO_SHOT_REACT_DESCRIPTION , πολύλογος = Αληθής
)
#configuring timecounter για να λάβετε τον χρόνο που χρησιμοποιείται για την πλήρη διαδικασία
μικρό = χρόνος . perf_counter ( )
καθήκοντα = [ μέσο. ασθένεια ( q ) Για q σε ερωτήσεις ]
αναμονή asyncio. μαζεύω ( *καθήκοντα )
παρήλθε = χρόνος . perf_counter ( ) - s
#print ο συνολικός χρόνος που χρησιμοποιήθηκε από τον πράκτορα για τη λήψη των απαντήσεων
Τυπώνω ( φά 'Ταυτόχρονη εκτέλεση σε {elapsed:0.2f} δευτερόλεπτα' )
Παραγωγή
Η ταυτόχρονη εκτέλεση εξάγει όλα τα δεδομένα ταυτόχρονα και παίρνει πολύ λιγότερο χρόνο από τη σειριακή εκτέλεση:
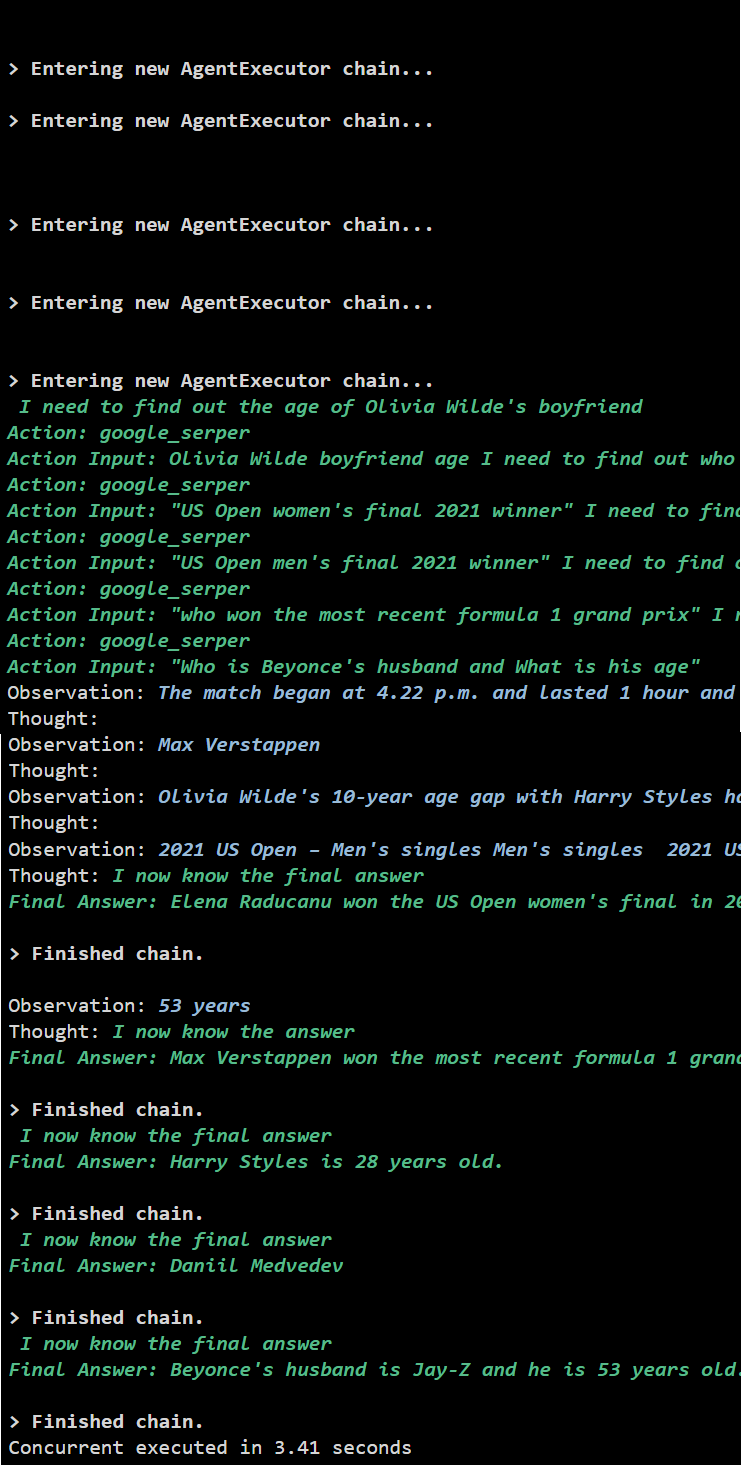
Αυτό αφορά τη χρήση του παράγοντα Async API στο LangChain.
συμπέρασμα
Για να χρησιμοποιήσετε τον παράγοντα Async API στο LangChain, απλώς εγκαταστήστε τις λειτουργικές μονάδες για να εισαγάγετε τις βιβλιοθήκες από τις εξαρτήσεις τους για να αποκτήσετε τη βιβλιοθήκη asyncio. Μετά από αυτό, ρυθμίστε τα περιβάλλοντα χρησιμοποιώντας τα κλειδιά OpenAI και Serper API πραγματοποιώντας είσοδο στους αντίστοιχους λογαριασμούς τους. Διαμορφώστε το σύνολο των ερωτήσεων που σχετίζονται με διαφορετικά θέματα και εκτελέστε τις αλυσίδες σειριακά και ταυτόχρονα για να λάβετε τον χρόνο εκτέλεσής τους. Αυτός ο οδηγός έχει επεξεργαστεί τη διαδικασία χρήσης του παράγοντα Async API στο LangChain.