Αυτό το άρθρο θα συζητήσει πώς να χρησιμοποιήσετε το API πολλαπλών λήψεων Elasticsearch για τη λήψη πολλών εγγράφων JSON με βάση τα αναγνωριστικά τους. Επιπλέον, το Elasticsearch σάς επιτρέπει να χρησιμοποιήσετε ένα ερώτημα λήψης για να ανακτήσετε τα έγγραφα από δείκτες χρησιμοποιώντας μόνο τα αναγνωριστικά εγγράφων.
Ας εξερευνήσουμε.
Αίτημα Σύνταξης
Ακολουθεί η σύνταξη για το Elasticsearch multi-get API:
GET /_mget
GET /
Το multi-get API υποστηρίζει πολλαπλούς δείκτες που σας επιτρέπουν να ανακτήσετε τα έγγραφα ακόμα κι αν δεν βρίσκονται στο ίδιο ευρετήριο.
Το αίτημα υποστηρίζει τις ακόλουθες παραμέτρους διαδρομής:
- <ευρετήριο> – Το όνομα του ευρετηρίου από το οποίο θα ανακτηθούν τα έγγραφα, όπως καθορίζεται από τα αναγνωριστικά τους.
Μπορείτε επίσης να καθορίσετε τις άλλες παραμέτρους ερωτήματος όπως φαίνεται:
- Προτίμηση – Καθορίζει τον προτιμώμενο κόμβο ή θραύσμα.
- Πραγματικός χρόνος – Εάν οριστεί σε true, η λειτουργία εκτελείται σε πραγματικό χρόνο.
- Φρεσκάρω – Αναγκάζει τη λειτουργία να ανανεώσει τα θραύσματα στόχου πριν από την ανάκτηση των καθορισμένων εγγράφων.
- Δρομολόγηση – Μια τιμή που χρησιμοποιείται για τη δρομολόγηση των λειτουργιών σε ένα συγκεκριμένο θραύσμα.
- Store_fields – Ανακτά τα πεδία εγγράφου που είναι αποθηκευμένα σε ένα ευρετήριο και όχι στο έγγραφο.
- _πηγή – Μια Boolean τιμή που καθορίζει εάν το αίτημα πρέπει να επιστρέψει το πεδίο _source ή όχι.
Το ερώτημα απαιτεί το σώμα, το οποίο περιλαμβάνει τις ακόλουθες τιμές:
- Έγγραφα – Καθορίζει τα έγγραφα που θέλετε να λάβετε. Επιπλέον, αυτή η ενότητα υποστηρίζει τα ακόλουθα χαρακτηριστικά:
- _ταυτότητα – Μοναδικό αναγνωριστικό του εγγράφου προορισμού.
- _δείκτης – Το ευρετήριο που περιέχει το έγγραφο προορισμού.
- Δρομολόγηση – Το κλειδί για το κύριο θραύσμα του εγγράφου.
- _πηγή – Εάν ισχύει, περιλαμβάνει όλα τα πεδία πηγής. διαφορετικά τους αποκλείει.
- _αποθηκευμένα_πεδία – Τα αποθηκευμένα_πεδία που θέλετε να συμπεριλάβετε.
- Αναγνωριστικά – Τα αναγνωριστικά των εγγράφων που θέλετε να λάβετε.
Παράδειγμα 1: Λήψη πολλαπλών εγγράφων από το ίδιο ευρετήριο
Το ακόλουθο παράδειγμα δείχνει πώς να χρησιμοποιήσετε το API πολλαπλών λήψεων Elasticsearch για να ανακτήσετε τα έγγραφα με συγκεκριμένα αναγνωριστικά από το ευρετήριο Netflix:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: αναφορά' -H 'Content-Type: application/json' -d'{
'έγγραφα': [
{
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_id': 'W3wnVoMBck2AEzXPytlJ'
}
]
}'
Το δεδομένο αίτημα θα πρέπει να λάβει τα έγγραφα με τα καθορισμένα αναγνωριστικά από το ευρετήριο Netflix. Η έξοδος που προκύπτει είναι όπως φαίνεται:
{'έγγραφα': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_version': 1,
'_seq_no': 0,
'_primary_term': 1,
'βρέθηκε': αλήθεια,
'_source': {
'διάρκεια': '90 λεπτά',
'listed_in': 'Ντοκιμαντέρ',
'country': 'Ηνωμένες Πολιτείες',
'date_added': '25 Σεπτεμβρίου 2021',
'show_id': 's1',
'σκηνοθέτης': 'Κίρστεν Τζόνσον',
'έτος_έκδοσης': 2020,
'βαθμολόγηση': 'PG-13',
'περιγραφή': 'Καθώς ο πατέρας της πλησιάζει στο τέλος της ζωής του, η κινηματογραφίστρια Kirsten Johnson σκηνοθετεί τον θάνατό του με εφευρετικούς και κωμικούς τρόπους για να τους βοηθήσει να αντιμετωπίσουν το αναπόφευκτο.',
'type': 'Ταινία',
'title': 'Ο Ντικ Τζόνσον είναι νεκρός'
}
},
{
'_index': 'netflix',
'_id': 'W3wnVoMBck2AEzXPytlJ',
'_version': 1,
'_seq_no': 12,
'_primary_term': 1,
'βρέθηκε': αλήθεια,
'_source': {
'χώρα': 'Γερμανία, Δημοκρατία της Τσεχίας',
'show_id': 's13',
'σκηνοθέτης': 'Κρίστιαν Σβόχοου',
'έτος_έκδοσης': 2021,
'βαθμολόγηση': 'TV-MA',
'περιγραφή': 'Αφού το μεγαλύτερο μέρος της οικογένειάς της δολοφονείται σε τρομοκρατική βομβιστική επίθεση, μια νεαρή γυναίκα παρασύρεται εν αγνοία του να ενταχθεί στην ίδια την ομάδα που τους σκότωσε.',
'type': 'Ταινία',
'τίτλος': 'Είμαι ο Καρλ',
'διάρκεια': '127 λεπτά',
'listed_in': 'Δράμα, διεθνείς ταινίες',
'cast': 'Luna Wedler, Jannis Niewöhner, Milan Peschel, Edin Hasanović, Anna Fialová, Marlon Boess, Victor Boccard, Fleur Geffrier, Aziz Dyab, Mélanie Fouché, Elizaveta Maximová',
'date_added': '23 Σεπτεμβρίου 2021'
}
}
]
}
Μπορούμε επίσης να απλοποιήσουμε το αίτημα βάζοντας τα αναγνωριστικά εγγράφων σε έναν απλό πίνακα όπως φαίνεται παρακάτω:
curl -XGET 'http://localhost:9200/netflix/_mget' -H 'kbn-xsrf: αναφορά' -H 'Content-Type: application/json' -d'{
'ids': ['T3wnVoMBck2AEzXPytlJ', 'W3wnVoMBck2AEzXPytlJ']
}'
Το προηγούμενο αίτημα θα πρέπει να εκτελέσει παρόμοια ενέργεια.
Παράδειγμα 2: Λήψη των εγγράφων από πολλαπλούς δείκτες
Στο ακόλουθο παράδειγμα, το αίτημα ανακτά πολλά έγγραφα από διαφορετικούς δείκτες όπως φαίνεται:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: αναφορά' -H 'Content-Type: application/json' -d'{
'έγγραφα': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ'
},
{
'_index': 'disney',
'_id': '8j4wWoMB1yF5VqfaKCE4'
}
]
}'
Η έξοδος που προκύπτει είναι όπως φαίνεται:

Παράδειγμα 3: Εξαίρεση συγκεκριμένων πεδίων
Μπορούμε να εξαιρέσουμε συγκεκριμένα πεδία από ένα δεδομένο αίτημα χρησιμοποιώντας τις παραμέτρους source_include και source_exclude.
Ένα παράδειγμα είναι όπως φαίνεται:
curl -XGET 'http://localhost:9200/_mget' -H 'kbn-xsrf: αναφορά' -H 'Content-Type: application/json' -d'{
'έγγραφα': [
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': ψευδής
},
{
'_index': 'netflix',
'_id': 'T3wnVoMBck2AEzXPytlJ',
'_source': {
'include': [ 'listed_in', 'release_year', 'title' ],
'exclude': [ 'description', 'type', 'date_added' ]
}
}
]
}'
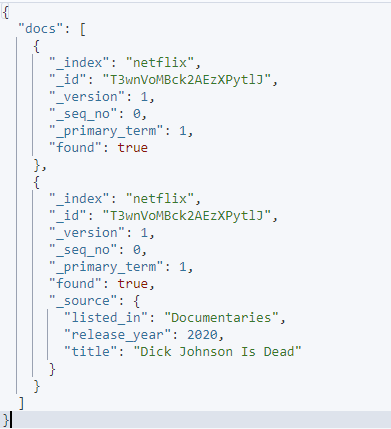
Το δεδομένο αίτημα χρησιμοποιεί την πηγή συμπερίληψης και εξαίρεσης για να καθορίσει ποια πεδία θέλετε να ανακτήσετε σε ένα δεδομένο έγγραφο.
Η έξοδος που προκύπτει είναι όπως φαίνεται:
συμπέρασμα
Σε αυτήν την ανάρτηση, συζητήσαμε τις βασικές αρχές της εργασίας με το Elasticsearch multi-get API το οποίο σας επιτρέπει να λαμβάνετε πολλά έγγραφα από διάφορες πηγές με βάση τα αναγνωριστικά τους. Μη διστάσετε να εξερευνήσετε τα άλλα έγγραφα για περισσότερες πληροφορίες.
Καλή κωδικοποίηση!